

First of all: Unfortunately, toilet paper cannot be digitized yet, but I can help you with everything else! Although, there are also paperless toilets. But that's another topic.
Invoices, contracts, notes - everything piles up and when you need a document, you spend ages looking for it. The usual paper chaos can be really annoying. The solution? A document management system (DMS)! And with Paperless, a document scanner and the Patch-T-Pages, you can not only efficiently digitize your documents, but also have them sorted automatically. Sounds good? Then let me show you how to set it all up! 💪
In another article, I've already explained the benefits of DMS Paperless and why you need it:

New Year's resolutions 🥳
Now, however, I wanted to digitize all(!) my documents over the holidays. Really all of them. I only realized later what I had let myself in for.
My fiancée works for a German government agency, so everything was neatly sorted in Leitz folders by person, subject and date, and there were also small inserts. Accurately punched and, if necessary, stapled. But after a good 12 years in a relationship, the folders simply become too much.
Much of it you don't even have to keep. I estimate that you only need to keep 10% of your everyday documents. This includes all documents from authorities, notices, contracts and generally everything from official bodies (notarial deeds, land register extracts, etc.). If you're filing a tax return, then of course everything that's included in it (invoices for business expenses, possibly also proof of payment such as bank statements).
Now I'm standing there with what feels like 100 folders that I have to digitize. Phew.
Of course you can do everything manually or with an app for Paperless, but that's not only annoying, it's also miserably inefficient. After all, I have better things to do with my time than spend hours turning pages and taking photos with my cell phone. So there is a great need for optimization.
But the disillusionment came quickly 🥱
In between the years, my printer also broke down, which is why I was looking for a good replacement that could also scan via a feeder and ideally even on both sides. But as we don't print that much now, I didn't want to spend €600, because such devices are more likely to be found in the professional sector and that's where it gets steep.
But it can only do ADF (Automatic Document Feeder) and no DADF (Duplex Automatic Document Feeder) and so scanning hundreds of documents would be really tedious. Been there, done that. So it became an HP OfficeJet Pro 8123e, purely for printing.

For single documents this is okay, but for a large number of documents or an initial digitization, this is nothing.
Document scanners for the win 🏆
Of course, I already knew document scanners from my professional environment. They have the great advantage that they are specialized for exactly these tasks and probably do them better than any consumer multifunction printer.

If you're not using an entry-level version, then it meets my requirements exactly:
- Fast and automatic (batch) feeding
- Duplex scan
- Detection of blank pages
- Double sheet detection (detects when more than one page is fed)
- Scanning of various formats (receipts, vouchers, receipts, etc.).)
- Storage of scans in a network share via WLAN or LAN#
- Can be used on its own (computer or cell phone)
- Optional: built-in OCR
After doing some research, I came across a ScanSnap iX1600 and bought it straight away.

Attach document scanner to Paperless 🔗
As Paperless, as mentioned in the other article, also has the ability to scan documents from a folder, you can have the scanner scan directly into the folder which can then be scanned by Paperless.

All you have to do is release the Consume folder in the network and make it known to the ScanSnap. To do this, at least in this model, you can create profiles in the software (not on the device itself). These are quite comprehensive and should actually offer everything you need as a semi-professional digitizer at home. Here is my profile for filing directly to the Paperless network share:
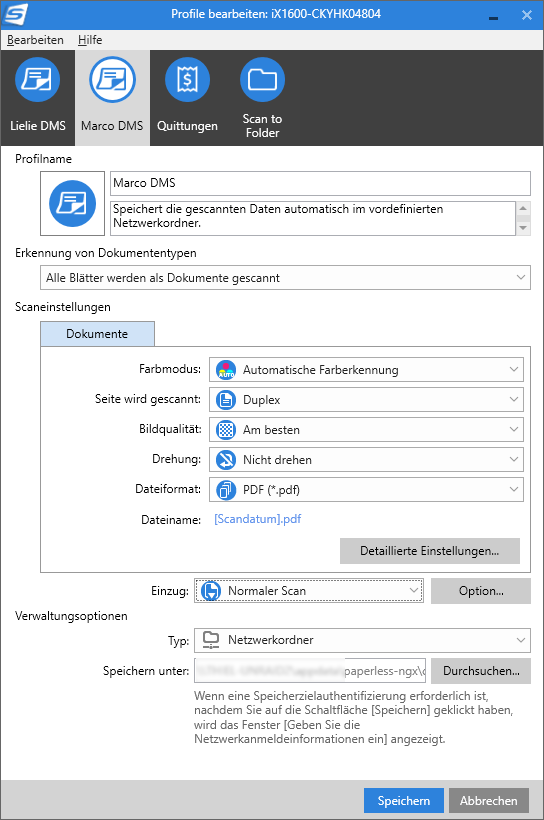
The most important settings here are that it scans duplex and files as a PDF to a network share so that Paperless can handle it. The profile is then stored in the software and in the device and can be used directly, even without a computer or cell phone.
But now you're probably asking yourself:
"Yes, but that's all well and good, I can only scan individual documents with it now, what if I want to scan a whole batch and each document should be in its own PDF?"
Yes, that's possible. Even easier than expected. 👇🏼
Separate batch scan into individual PDFs 📖
Paperless can already do this and there is an industry standard for this too.
This is called PATCH(-T). This is just a delimiter page that is equipped with a barcode. If Paperless recognizes this page, it separates the documents into individual PDFs. Such a PATCH-T page looks like this:

You can easily download them here:
But unfortunately that's not it yet. You first have to activate the detection feature in Paperless. However, this is quite simple via the environment variables (if you host Paperless in Docker):
PAPERLESS_CONSUMER_ENABLE_BARCODES: trueThat's enough. However, you can also define your own strings with PAPERLESS_CONSUMER_BARCODE_STRING. The documentation says:
Enables the scanning and page separation based on detected barcodes. This allows for scanning and adding multiple documents per uploaded file, which are separated by one or multiple barcode pages. For ease of use, it is suggested to use a standardized separation page, e.g. here. If no barcodes are detected in the uploaded file, no page separation will happen.The original document will be removed and the separated pages will be saved as pdf. See additional information in the advanced usage documentation. Defaults to false.
So in plain language:
You look for a bunch of documents, separate each document from others with such a PATCH-T page and Paperless does the rest. But you should print out this PATCH-T page a few times.
The documents are separated exactly at the point of the PATCH-T page and stored in individual PDFs and processed accordingly. Don't worry, the PATCH-T pages don't end up in your scan, Paperless sorts them out nicely.
Blank pages are a problem 🪹
After I had scanned the first batch (which was almost 30 documents), I noticed more and more that the ScanSnap recognizes blank pages well, but not always. This apparently has to do with the fact that the PATCH-T pages that I printed at the beginning were of course only printed on one side. As a result, it sometimes happened that the document started with a blank page after the PATCH-T page. This mainly affected pages that were not completely clean and had probably exceeded the threshold of white, so that the ScanSnap thought "Hey, there's something on it, I'll scan that too".
But there is also a solution for this completely in Paperless. This is where the PreConsume scripts come into play.
This allows you to intervene in the process of processing and have things done, in this case a script that recognizes and sorts out empty pages based on a threshold value.
To do this, you define the path to a script as an environment variable
PAPERLESS_PRE_CONSUME_SCRIPT: /usr/src/paperless/scripts/pre-consume.shThe script there is just a collection file for all scripts so that I don't have to adapt the container again. The script therefore only integrates other scripts in turn:
#!/bin/sh
set -x
# Remove blank pages
/usr/src/paperless/scripts/remove-blank-pages.shThe really exciting thing is the remove-blank-pages.sh script:
#!/bin/bash
#set -x -e -o pipefail
set -e -o pipefail
export LC_ALL=C
#IN="$1"
IN="$DOCUMENT_WORKING_PATH"
# Check for PDF format
TYPE=$(file -b "$IN")
if [ "${TYPE%%,*}" != "PDF document" ]; then
>&2 echo "Skipping $IN - non PDF [$TYPE]."
exit 0
fi
# PDF file - proceed
#PAGES=$(pdfinfo "$IN" | grep ^Pages: | tr -dc '0-9')
PAGES=$(pdfinfo "$IN" | awk '/Pages:/ {print $2}')
>&2 echo Total pages $PAGES
# Threshold for HP scanners
# THRESHOLD=1
# Threshold for Canon MX925
THRESHOLD=1
non_blank() {
for i in $(seq 1 $PAGES) ; do
PERCENT=$(gs -o - -dFirstPage=${i} -dLastPage=${i} -sDEVICE=ink_cov "${IN}" | grep CMYK | nawk 'BEGIN { sum=0; } {sum += $1 + $2 + $3 + $4;} END { printf "%.5f\n", sum } ')
>&2 echo -n "Color-sum in page $i is $PERCENT: "
if awk "BEGIN { exit !($PERCENT > $THRESHOLD) }"; then
echo $i
>&2 echo "Page added to document"
else
>&2 echo "Page removed from document"
fi
done
}
NON_BLANK=$(non_blank)
if [ -n "$NON_BLANK" ]; then
NON_BLANK=$(echo $NON_BLANK | tr ' ' ",")
qpdf "$IN" --replace-input --pages . $NON_BLANK --
fi
And if there are several people? 🧑🏼👩🏼👧🏼
Paperless also has a solution for this. Paperless can run through the Consume folder recursively, i.e. also search through subfolders, and apply tags or owners directly based on this. All you have to do is activate the environment variable PAPERLESS_CONSUMER_RECURSIVE, store various folders there (e.g. the names of the people receiving the documents) and then create a workflow in Paperless. Alternatively, you could also have the directory names automatically created as tags (using the environment variable PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS and then place workflows on them, but I didn't want to do that.
You can then use the workflows to place an "automation" on the path:
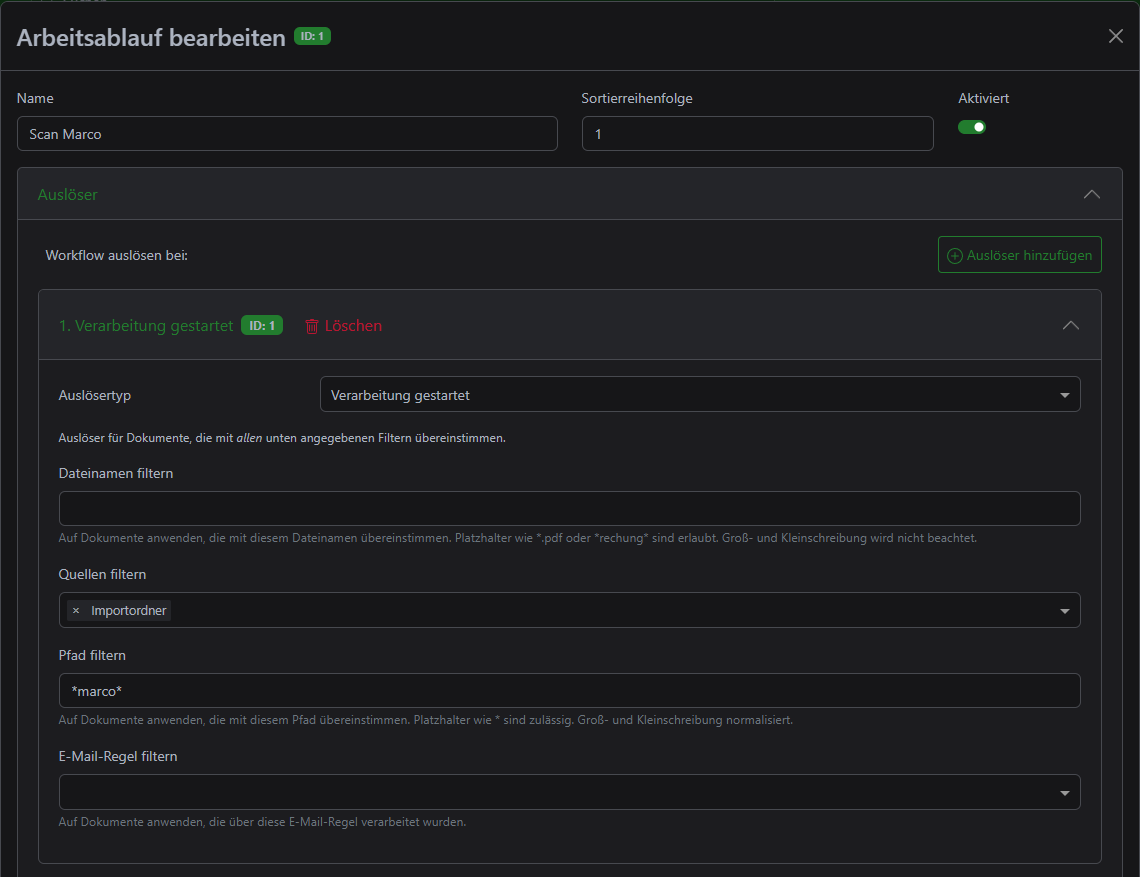
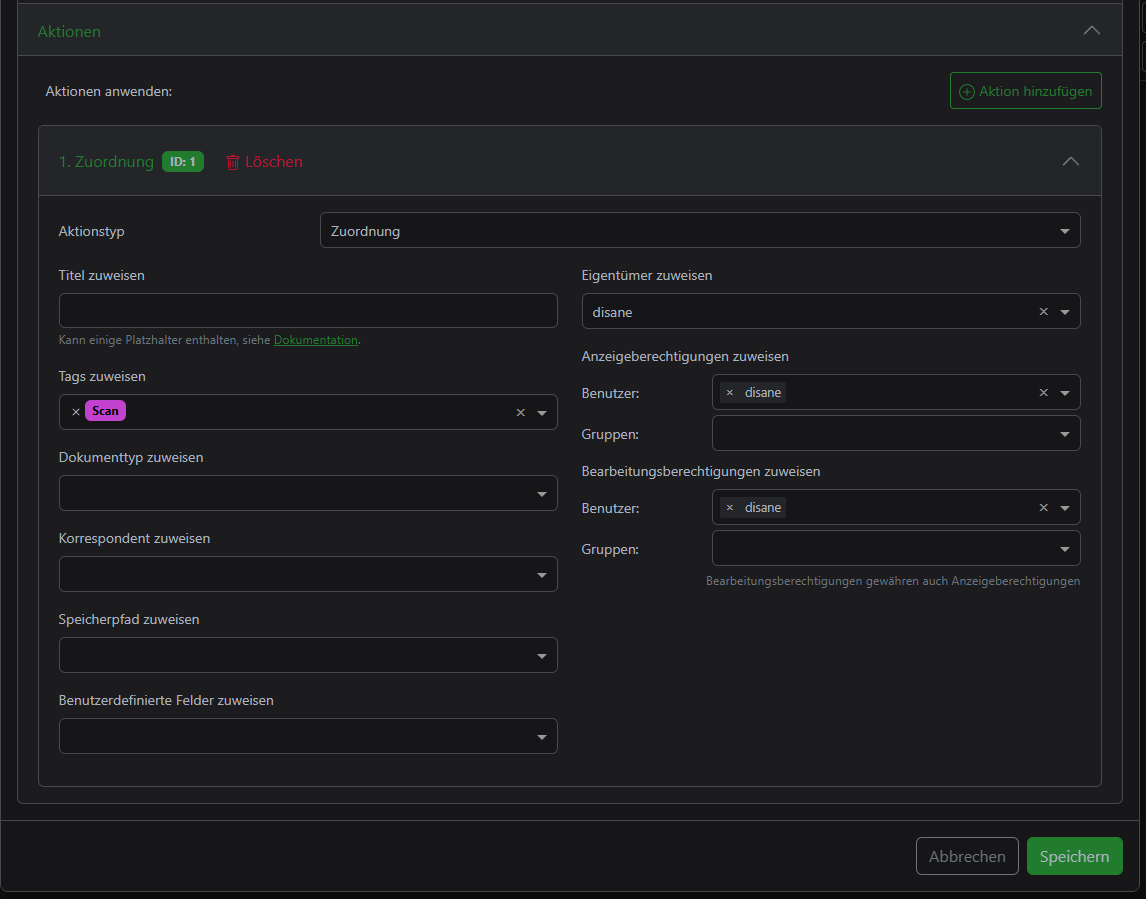
And I have the document scanner's profile scanned into precisely this path. I have also created a profile and a workflow for my fiancée. If I now scan documents of mine, I select my profile and everything from the folder is automatically assigned an owner and optionally tags and other assignments. It's the same with my fiancée's documents, just in a different folder in the file share.
Since you can work with regex, you can create quite generous and detailed queries.

But there is a problem 🥴
These workflows are not executed if the batch scan runs via PATCH-T pages and pages are to be separated automatically. This doesn't seem to be a bug either, but is, at least currently, "made by intention". I once reported this as a bug at Paperless:
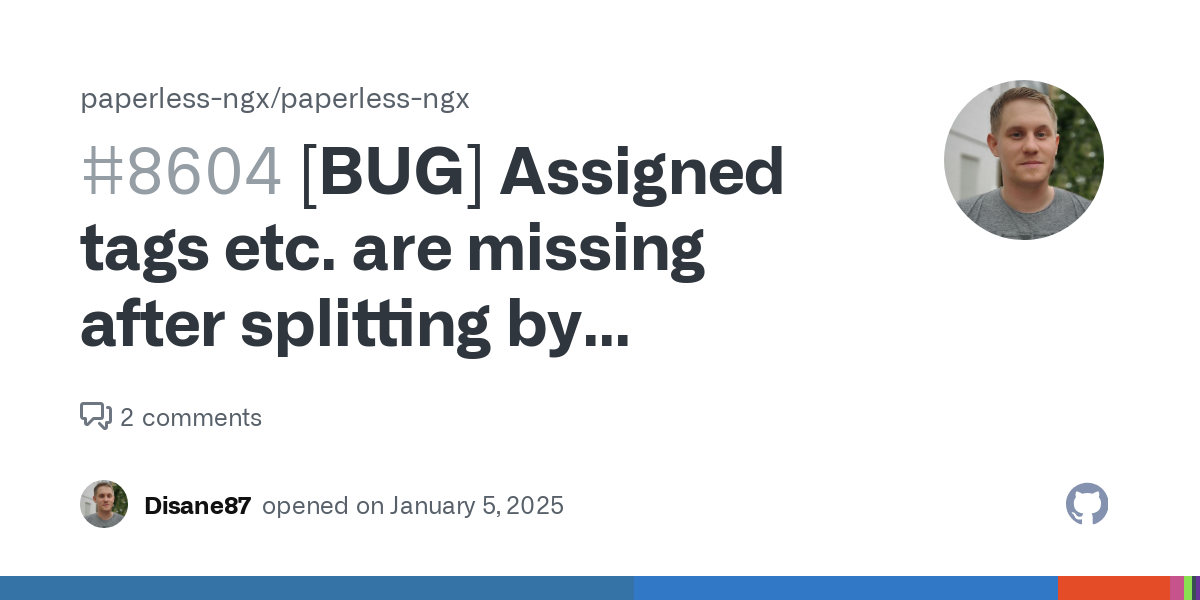
So for you: Many documents then have to be manually tagged with owners or other tags, but individual scans work without any problems, so that at least the individual scanning should not cause any problems with the workflows.
I have helped myself by scanning all documents, separated by person, in a batch, marking them with the multiple selection in Paperless and assigning users. I haven't found a better workflow yet.
The only important thing is that you automatically save the documents with a unchecked or todo tag so that you can find them again later.
Workflows take work off your hands 🧑🏼🏭
In general, however, the workflows are worth their weight in gold. For example, I have created a workflow that reacts to certain document types and tags and adds another tag. This allows me to categorize whether a document could be relevant under tax law and then, at the end of the year, I can narrow it down to one year via a user-defined view and see everything I need to include in my upcoming tax return.
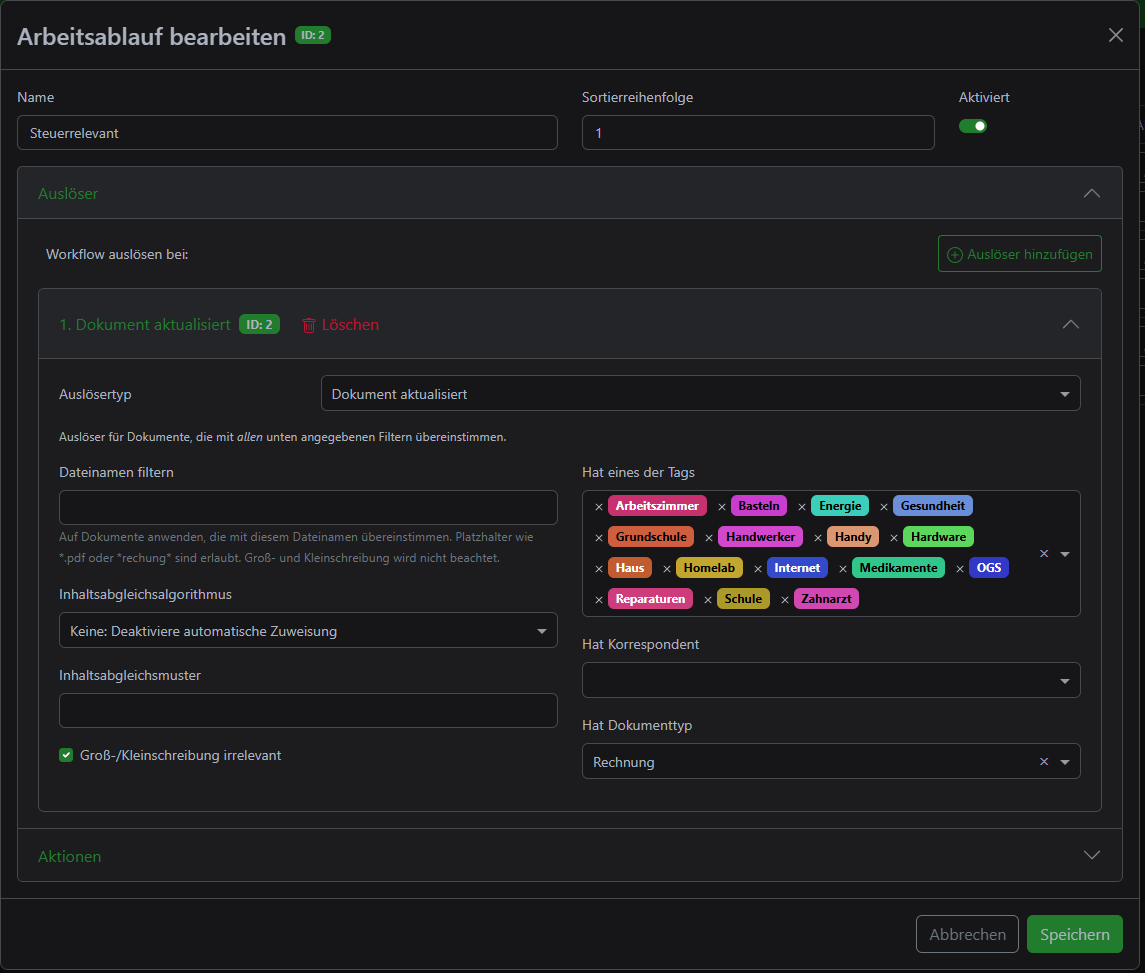
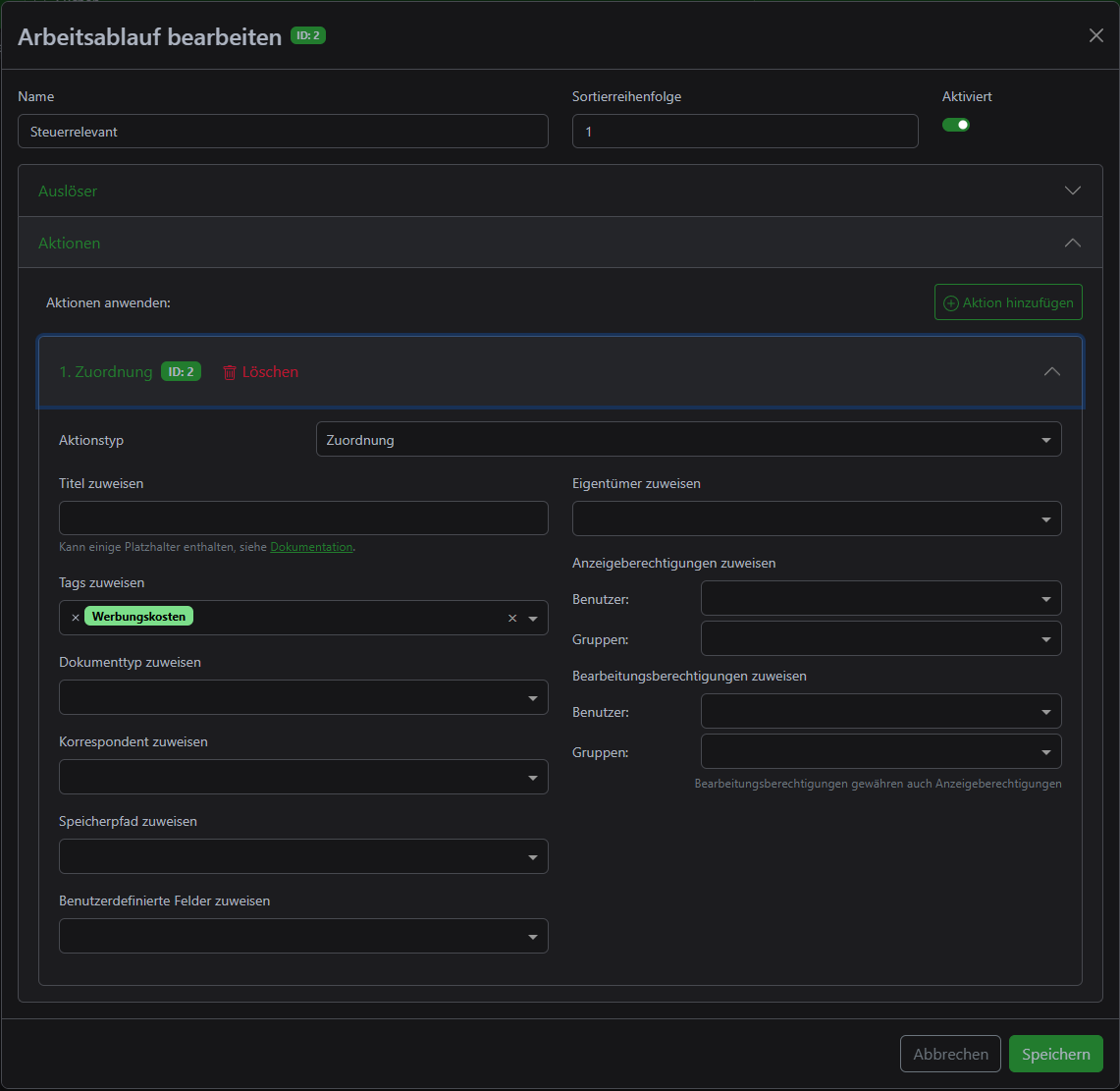
Goodbye folder 👋🏼
With all the customizations or workflows, I can now digitize all my documents once and throw all folders in the trash. In principle, I can also shred all digitized documents as long as I don't need to keep them.
Because this definitely makes your folders a lot less cluttered, you can now make use of the ASN in Paperless. The ASN (Archive Serial Number) is basically an archive number for a document so that it can be physically found again quickly. Each document automatically receives one and can also be assigned a different one if necessary. In this way, you can assign this ASN to all physical documents (whether stamped or glued) and then store them in a folder. You could also use inserts to create a certain order and separate the documents thematically.
This way, if you ever need your physical documents, you can find them quickly and reliably and don't have to search for them.
I'm not currently using this method, but I'm actually thinking about introducing it at some point. At the moment, however, I'm not yet ready to shred all my documents.
No document scanner necessary 🫰🏼
As I found out later, the document scanner would not have been necessary in principle, as Paperless can also automatically merge documents using a single-sided scan. There is the environment variable PAPERLESS_CONSUMER_ENABLE_COLLATE_DOUBLE_SIDED for this. This allows you to first scan and file all even pages and then turn the stack over and file all odd pages, Paperless then recognizes that they belong together and merges them into one PDF. The process and its pitfalls are described in the Paperless documentation:
This means that you wouldn't need an expensive document scanner with DADF scanning, but can also use a normal consumer printer with ADF scanning. But the documentation also describes that the process can be quite error-prone and I didn't want to have to check all the scanned documents. The solution with the document scanner was actually worth the money to me because it saves me any headaches.
Conclusion 💡
As you can see, it's quite easy to quickly and efficiently store all your previous documents in Paperless and process them (almost) completely automatically. In some areas, you still have to do a bit of work in Paperless or come up with simple solutions. But it's all better than scanning everything manually and you quickly get a status that you can continue working with.
In 3 evenings, I managed to scan almost 4 Leitz folders with almost 700 documents. What more could you want?
Discover more articles

Wie ich Massen an Dokumenten digitalisiert habe 🧻
Wie ich mit Hilfe des DMS Paperless und einigen Tweaks Massen an Dokumenten digitalisiert habe, zeige ich dir in diesem Artikel 🚀

Wegweisendes Urteil für mehr Verbraucherschutz bei Online-Coachings 🚀
Ein neues Urteil stärkt Kundenrechte bei Online-Coachings und könnte die gesamte Branche verändern ⚖️

Everyone needs a DMS at home
Do your documents pile up in folders? Just digitize them 📃