

Everyone is probably familiar with this. New letters keep arriving in the post or invoices via email. But what to do with them? Especially with regard to the annual tax return, it is important to have a good and fast system so that you can find everything again if necessary (or not). 😶🌫️
A DMS (Document Management System) is designed to solve precisely this problem by storing all documents digitally. Modern DMS also offer additional features such as automatic tagging, OCR (to extract metadata), automatic assignments, etc.

How did I solve this before? 🤔
Until a few years ago, I moved all invoices that came via email to an extra folder in my IMAP mailbox. This was not only annoying, but also stupid, as you always had to manually move the emails and then open the PDF again later to find out what had happened there.
This had to change!
As I am a professional software developer and also have an insight into how companies work with this topic, the keyword DMS quickly came up. But a business DMS, such as Microsoft's SharePoint, is simply too "fat" for home use, too expensive and sometimes has to be painstakingly adapted. Apart from the training period.
After a long search, Florian (https://wartner.io) brought Paperless-ngx to my attention.
 paperless-ngx
paperless-ngxThe big advantage is that it is free, independent of the cloud and is located in my home. It also offers some other cool features that are or could be very useful (a small excerpt from the document):
- Organize and index your scanned documents with tags, correspondents, types, and more.
- Performs OCR on your documents, adding searchable and selectable text, even to documents scanned with only images.
- Utilizes the open-source Tesseract engine to recognize more than 100 languages.
- Documents are saved as PDF/A format which is designed for long term storage, alongside the unaltered originals.
- Uses machine-learning to automatically add tags, correspondents and document types to your documents.
- Supports PDF documents, images, plain text files, Office documents (Word, Excel, Powerpoint, and LibreOffice equivalents)1 and more.
- Paperless stores your documents plain on disk. Filenames and folders are managed by paperless and their format can be configured freely with different configurations assigned to different documents.
- Beautiful, modern web application
- Full text search helps you find what you need:
- Auto completion suggests relevant words from your documents.
- Results are sorted by relevance to your search query.
- Highlighting shows you which parts of the document matched the query.
- Searching for similar documents ("More like this")
- Email processing: import documents from your email accounts:
- Configure multiple accounts and rules for each account.
- After processing, paperless can perform actions on the messages such as marking as read, deleting and more.
- A built-in robust multi-user permissions system that supports 'global' permissions as well as per document or object.
- A powerful templating system that gives you more control over the consumption pipeline.
- Optimized for multi core systems: Paperless-ngx consumes multiple documents in parallel.
- The integrated sanity checker makes sure that your document archive is in good health.
Wow! This is exactly what I need!

The installation 🛠️
The setup is quite easy to do via Docker. There are ready-made apps for Unraid or you can simply use the included script for installation. The installation is very well described in the documentation. However, it should be mentioned that Paperless only runs on Linux.
It would also run without Docker, but Docker has many advantages (which I will be happy to write about in a separate article if required).
If you already have a Docker host, you can also use my Stack for this (you may have to adjust paths and the networks used). A Redis broker and a database (Postgres) are also integrated here:
version: "3.6"
networks:
homelab:
name: br1
external: true
dms-internal:
services:
broker:
networks:
- dms-internal
image: redis:6.2
deploy:
restart_policy:
condition: on-failure
volumes:
- /mnt/user/appdata/paperless-ngx/redis:/data
db:
networks:
- dms-internal
image: postgres:14
volumes:
- /mnt/user/appdata/paperless-ngx/db:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: [db user]
POSTGRES_PASSWORD: [db password]
webserver:
networks:
- homelab
- dms-internal
image: ghcr.io/paperless-ngx/paperless-ngx:latest
deploy:
restart_policy:
condition: on-failure
depends_on:
- db
- broker
ports:
- 8777:8000
volumes:
- /mnt/user/appdata/paperless-ngx/data:/usr/src/paperless/data
- /mnt/user/appdata/paperless-ngx/media:/usr/src/paperless/media
- /mnt/user/appdata/paperless-ngx/export:/usr/src/paperless/export
- /mnt/user/appdata/paperless-ngx/consume:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
USERMAP_UID: 1026
USERMAP_GID: 100
PAPERLESS_TIME_ZONE: Europe/Berlin
PAPERLESS_ADMIN_USER: [user]
PAPERLESS_ADMIN_PASSWORD: [password]
PAPERLESS_OCR_LANGUAGE: deu+eng
PAPERLESS_URL: [url]
PAPERLESS_FILENAME_FORMAT: "{created_year}/{correspondent}/{created_month}{created_day}_{title}"By running this as a Docker stack, I also have the option of having a kind of high-availability in the event of a failure (possibly on several host systems).
Setting up Paperless 🍃
Once the stack is running, you can simply go to the shared website. You will then see the login screen, where you can log in with the data of the environment variables PAPERLESS_ADMIN_USERand PAPERLESS_ADMIN_PASSWORD.
This would set up the system, but it would still be empty. You could already drag PDFs into the system and the magic would begin ✨
Which magic does Paperless do? 🧙
This is explained quite simply. When Paperless receives a document, it performs an OCR. OCR (optical character recognition) is nothing more than digitizing the text. It is therefore full-text capable. In addition to the OCR, a local AI is also trained in the background, which can suggest, recognize and even completely take over many things.
So if you keep tagging your invoices with "For the house", Paperless will always do this in the future. But Paperless goes even further here. It includes the OCR in the training of the AI. At some point, Paperless will recognize that your annual electricity bill (which you have tagged with Electricity, Energy and Household in the past) should probably be treated in the same way in the future. So the more you import and tag, the more Paperless can do for you in the future.
This also works very well, for example, with Amazon invoices that I import manually. Paperless recognizes quite reliably what is household stuff and what is hardware for my HomeLab. Very very nice!

More options
Paperless offers many options for storing and managing your documents. You can also create different paths for certain document types. It offers user management (particularly useful for families) and the option to maintain even more data in your documents using user-defined fields. In addition, you also have the option of automatic archiving so that your documents are always available (especially useful for tax purposes or for self-employed people).
E-mail connection 📯
Since you probably also receive a lot of emails with invoices, you can also connect your mailbox via IMAP and search for certain keywords and have the PDFs automatically imported into Paperless. To do this, you can simply go to the settings under Email:

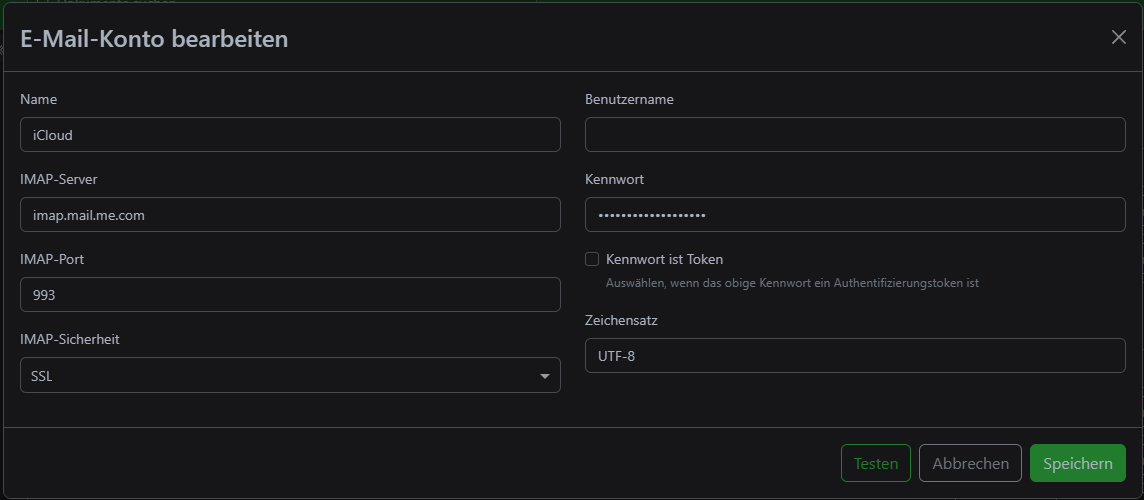
Here you then create email accounts to which Paperless should connect:
Now it's getting interesting. You can now create rules for this mailbox. I have created a rule that searches for the keyword "invoice" in the email and only processes this:
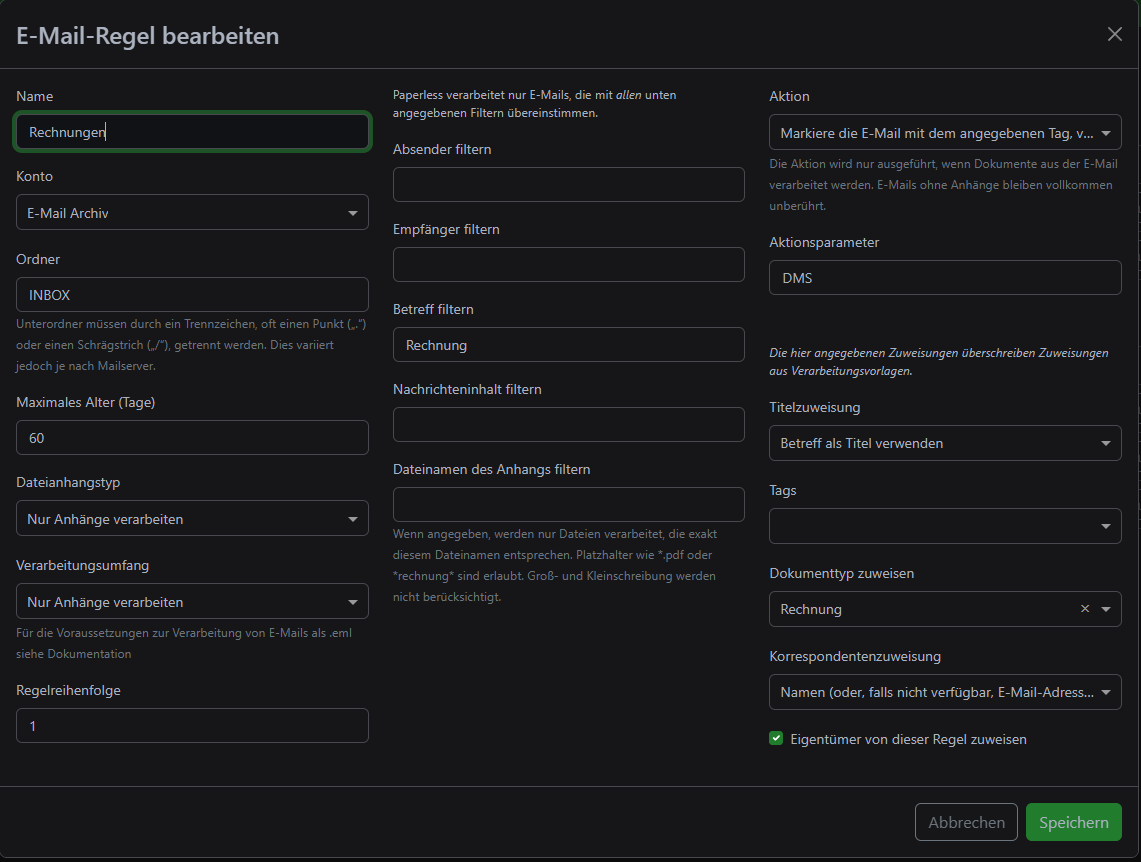
You are very flexible here. You can also search through emails only for certain senders, you can check the content and/or assign tags, specify document types and much more.
My rule says that the keyword "invoice" should be searched for in the subject line. Only the INBOX folder is searched (you can also specify others). If there is a match, the system checks whether PDFs are available as attachments and the document type is preset to Invoice. In addition, a correspondent is also created (is practically a contact management). YOU could also assign tags here, e.g: unchecked. This way you know later that you still need to check this document.
And how do I get documents that have already been digitized imported? 📫
There are several ways to do this. If there are only a few documents, you can simply drag and drop them into Paperless and they will be processed immediately. Alternatively, you can also specify a folder for Consume during setup. This folder is designed so that you can simply drop PDFs into it and everything will be processed.
If you are a little more familiar with programming, you can also use the REST API from Paperless and even connect other programs.
What do I do with letters? 💌
There are solutions here too. Paperless also offers apps for common mobile operating systems, which you can use to easily scan letters. Alternatively, you can also use a document scanner that stores the documents in the Consume directory. However, your Consume directory must be shared for this.
Custom overviews 🖥️
In Paperless, you also have the option of creating your own overviews from the search. I have created an overview of all invoices and all documents that I still need to check:
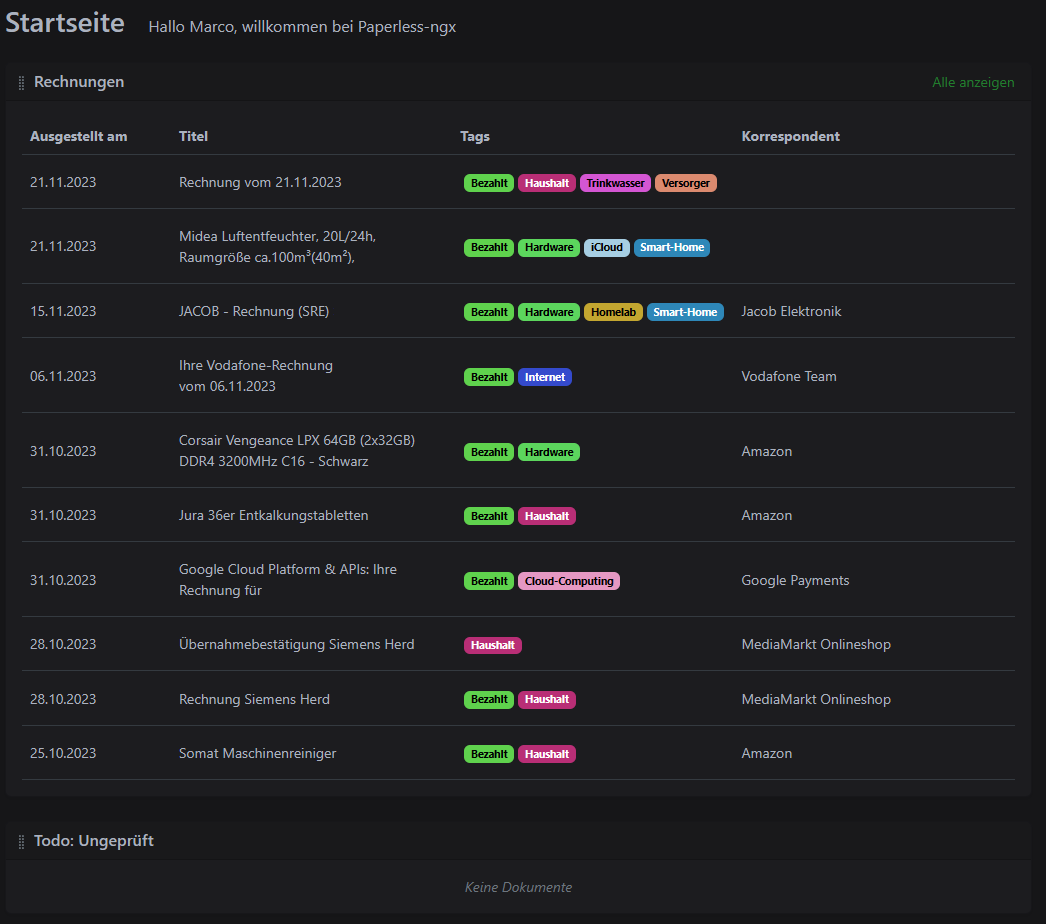
But you are completely free to decide what and how you want to do this to keep an overview.
You can also create overviews that show you all the invoices for hardware for the current year so that you can declare them later for tax purposes. The limits are really only set by how you manage, tag and file your documents.
Conclusion
If you also have recurring problems with documents or you have piles of folders lying around at home, I can only warmly recommend Paperless to you! You'll love it, just like I do now ❤️
How do you see the topic? Would Paperless be something for you? Or how do you manage your documents? Let me know in the comments 👇
Discover more articles

Jeder braucht ein DMS zuhause
Deine Dokumente stapeln sich in Ordnern? Digitalisiere sie doch einfach 📃

Heizungen automatisiert ein- und ausschalten
Du willst deine Heizungsthermostate automatisiert steuern über Tür und Fensterkontakte in Home Assistant? Ich zeig dir wie es geht 🎉

How I digitized masses of documents 🧻
In this article, I'll show you how I digitized masses of documents with the help of DMS Paperless and a few tweaks 🚀

Download Amazon invoices automatically
I often order from Amazon, from hardware to other things. Since Amazon doesn't send invoices by email and I need them in my DMS, I've now found a solution for this. 🔥